JPA에서 엔티티를 매핑시에 사용되는 어노테이션은 다음과 같습니다.
- 객체와 테이블 매핑: @Entity, @Table
- 필드와 컬럼 매핑 : @Column
- 기본 키 매핑 : @Id
- 연관관계 매핑: @ManyToOne, @JoinColumn
@Entity
@Entity가 붙은 클래스는 JPA를 사용하여 실제 테이블과 매핑할 클래스이며 필수로 사용해야 하는 어노테이션이며 사용시 유의해야 할 사항은 다음과 같습니다.
- 기본 생성자 필수(파라미터가 없는 public 또는 protected 생성자)
- final 클래스, enum, interface, inner 클래스 사용 X
- 저장할 필드에 final 사용 X
@Table
@Table 어노테이션은 엔티티와 매핑할 테이블을 지정하며 다음과 같은 속성을 지원합니다.
- name : 매핑할 테이블 이름 (기본으로 엔티티 이름을 사용)
- catalog : 데이터베이스 catalog 매핑
- schema : 데이터베이스 schema 매핑
- uniqueConstraints : DDL 생성 시에 유니크 제약 조건 생성
데이터베이스 스키마 자동 생성
일반적으로 운영 상황에서는 사용하면 안되며, 사용하더라도 생성된 DDL을 토대로 적절히 다듬어서 사용해야 합니다.
- 속성
- create : 기존테이블 삭제 후 다시 생성 (DROP + CREATE)
- create-drop : create와 같으나 종료 시점에 테이블 DROP
- update : 변경분만 반영 (운영DB에는 사용하면 안됨)
- validate : 엔티티와 테이블이 정상 매핑 되었는지만 확인
- none : 사용하지 않음
- 주의사항
- 운영 장비에서는 절대 create, create-drop, update 사용하면 안된다.
- 개발 초기 단계에는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
- DDL 생성 기능 예제
-
제약조건 추가 : 회원 이름은 필수, 10자 초과 X
- @Column(nullabel = false, length = 10)
-
유니크 제약조건 추가
- @Table(uniqueConstraints = {@UniqueConstraint( name = “NAMEAGEUNIQUE”, columnNames={”NAME”, “AGE”} )})
- DDL 생성 기능은 DDL 자동 생성할 때만 사용되고 실행 로직에는 영향을 주지 않는다.
필드와 컬럼 매핑
객체 내 필드와 컬럼을 매핑하는 방법을 알아보겠습니다. 먼저 다음과 같은 간단한 요구사항이 있다고 가정해보겠습니다.
- 회원은 일반 회원과 관리자로 구분해야 한다.
- 회원 가입일과 수정일이 있어야 한다.
- 회원을 설명할 수 있는 필드가 있어야 한다. 이 필드는 길이 제한이 없다.
위 요구사항을 충족하는 JPA Entity는 다음과 같이 생성됩니다.
@Entity
public class Member {
@Id
private Long id;
@Column(name = "name")
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Lob
private String description;
// Getter, Setter ...
}필드와 컬럼을 매핑할 때 사용되는 어노테이션은 다음과 같습니다.
-
@Column : 컬럼 매핑
- name : 필드와 매핑할 테이블의 컬럼 이름
- insertable, updatable : 등록, 변경 가능 여부
- nullable(DDL) : null 값의 허용 여부를 설정
- unique(DDL) : @Table의 uniqueConstraints와 같으나 한 컬럼에 간단히 설정시 사용
- columnDefinition(DDL) : 데이터베이스 컬럼 정보를 직접 줄 수 있음
- length(DDL) : 문자 길이 제약조건, STring 타입에만 사용
- precision, scale(DDL) : BigDecimal 타입에서 사용하며 아주 큰 숫자나 정밀한 소수를 다룰 때 사용
-
@Temporal : 날짜 타입 매핑 (최신 버전에서는 생략 가능)
- TemporalType.DATE : 날짜, DB date 타입과 매핑 (2025-01-02)
- TemporalType.TIME : 시간, DB time 타입과 매핑 (09:00:00)
- TemporalType.TIMESTAMP : 날짜와 시간, DB의 timestamp와 매핑 (2025-01-02 09:00:00)
-
@Enumerated : enum 타입 매핑 (deafult : EnumType.ORDINAL)
- EnumType.ORDINAL: enum 순서를 DB에 저장
- EnumTypes.STRING: enum 이름을 DB에 저장
- ORDINAL의 경우
순서만 기억하고 있기 때문에 쓰지 않는걸 권장
-
@Lob : BLOB, CLOB 매핑
- CLOB : String, char[], java.sql.CLOB
- BLOB: byte[], java.sql.BLOB
-
@Transient : 특정 필드를 컬럼에 매핑하지 않음 (매핑 무시)
- 필드 매핑 X
- DB에 저장X, 조회X
- 메모리상에만 임시로 데이터를 저장할 때 사용
기본 키 매핑
기본 키 매핑시 지원되는 어노테이션은 다음과 같습니다.
- @Id (직접 할당)
-
@GenerateValue (자동 생성)
- IDENTITY : DB에 위임, MYSQL
-
SEQUENCE : DB 시퀀스 오브젝트 사용, ORACLE
- @SequenceGenerator 필요
-
TABLE : 키 생성용 테이블 사용, 모든 DB에서 사용
- @TableGenerator 필요
- AUTO : 방언에 따라 자동 지정, 기본 값
특수한 경우가 아니라면 자동 생성 전략을 많이 사용하며 각 자동 생성 전략에 따른 특징은 다음과 같습니다.
IDENTITY 전략
- 기본 키 생성을 DB에 위임
-
주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용
(MySQL의 AUTO_INCREMENT)
- JPA는 보통 트랜잭션 커밋 시점에 INSERT SQL 실행
- AUTO_INCREMENT는 DB에 INSERT SQL을 실행한 후 ID 값을 알 수 있음
-
IDENTITY 전략은 em.persist() 시점에 즉시 INSERT SQL 실행 후 DB에서 식별자 조회
- 일반적으로 1차 캐싱으로 인해 트랜잭션 commit시 insert query가 발생하나 IDENTITY 전략 사용시에 예외로 영속시 Insert 쿼리가 발생하여
모아서 Insert 불가
- 일반적으로 1차 캐싱으로 인해 트랜잭션 commit시 insert query가 발생하나 IDENTITY 전략 사용시에 예외로 영속시 Insert 쿼리가 발생하여
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}
Member member = new Member();
member.setId(1L);
member.setName(":HelloA");
em.persist(member); // 여기서 Insert SQL문이 실행된다.
tx. commit();SEQUENCE 전략
-
DB 시퀀스는 유일한 값을 순서대로 생성하는 특별한 DB 오브젝트
(오라클 시퀀스)
- 오라클, PostgreSQL, DB2, H2 DB에서 사용
-
속성
- name : 식별자 생성기 이름 (required)
- sequenceName : DB에 등록되어 있는 시퀀스 이름
- initalValue : DDL 생성 시에만 사용되며 처음 1 시작하는 수 지정
-
allocationSize : 시퀀스 한 번에 호출하는 증가 수
- 성능 최적화에 사용되며 DB 설정상 하나씩 증가되도록 설정되어 있으면 반드시 1로 설정
- default인 50으로 설정시 DB에는 먼저 50개 증가시킨 후 어플리케이션 메모리상에서 하나씩 꺼내어 사용 (성능 ✅ ,동시성 이슈 ✅)
- catalog, schema : DB catalog, schema 이름
@Entity
@SequenceGenerator(
name = “MEMBER_SEQ_GENERATOR",
sequenceName = “MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 1
)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id;TABLE 전략
- 키 생성 전용 테이블을 만들어 DB 시퀀스를 흉내
- 장점 : 모든 DB에 적용 가능
- 단점 : 성능
-
속성
- name : 식별자 생성기 이름
- table 키 생성 테이블명
- pkColumnName : 시퀀스 컬럼명
- valueColumnNa : 시퀀스 값 컬럼명
- pkColumnValue : 키로 사용할 값 이름
- initalValue : 초기 값, 마지막으로 생성된 값이 기준
- allocationSize : 시퀀스 한 번 호출에 증가하는 수
- catalog, schema : DB catalog, schema 이름
- uniqueConstaints : 유니크 제약 조건 지정
권장하는 식별자 전략
- 기본 키 제약 조건 : null 아님, 유일, 변하면 안됨.
- 미래까지 이 조건을 만족하는 자연키는 찾기 어렵다. 대리키(대체키)를 사용하자.
- 예를 들어 주민등록번호도 기본 키로 적절하지 않다.
권장 : Long형 + 대체키 + 키 생성전략 사용
위 내용을 바탕으로 아래 요구 사항을 충족하는 간단한 JPA 실습을 진행해보겠습니다.
- 요구사항
- 회원은 상품을 주문할 수 있다.
- 주문 시 여러 종류의 상품을 선택할 수 있다.
- 기능 목록
-
회원 기능
- 회원등록
- 회원조회
-
상품 기능
- 상품등록
- 상품수정
- 상품조회
-
주문 기능
- 상품주문
- 주문내역조회
- 주문취소
- 도메인 모델 분석
- 회원과 주문의 관계 : 회원은 여러 번 주문할 수 있다. (일대다)
- 주문과 상품의 관계 : 주문할 때 여러 상품을 선택할 수 있다. 반대로 같은 상품도 여러 번 주문될 수 있다. 주문상품 이라는 모델을 만들어서 다대다 관계를 일대다, 다대일 관계로 풀어냄.
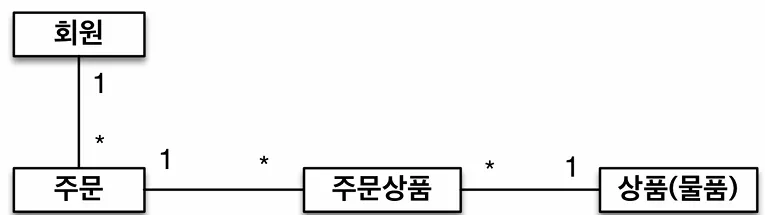
- 테이블 설계
- 엔티티 설계 및 매핑
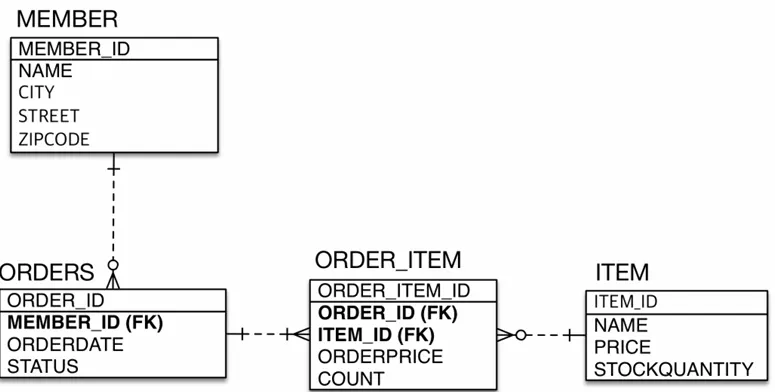
위 내용 베이스 구현 코드는 아래 repo 참조
https://github.com/bangddong/study-jpa
이 링크를 통해 구매하시면 제가 수익을 받을 수 있어요. 🤗